This is a heads‑up about the Software Heritage project if you need to archive and then reference your software generally — or perhaps refer to a particular release, individual file, or specific few lines of code using a robust identifier.
Indeed, your favorite software repository (repo) might already be there — having been earlier scraped by Software Heritage as part of their routine activities.
Introduction
Software Heritage is a dedicated project, first developed by the French Institute for Research in Computer Science and Automation (inria), and now constituted as a non‑profit organization based in France. The project seeks to archive all publicly available historical and contemporary software as a service to humanity — with a focus on human readable source code. The project is also designed to be permanent and enduring and operates several geographically diverse mirrors.
Software Heritage supports the Git, Mercurial, Subversion, and Bazaar versioning systems. And, as indicated, Software Heritage invests considerable effort scraping from known code hosting sites, including GitHub and GitLab.com. If not, you can manually add a codebase if your repo is public and visible and accessible via either HTTPS or SSH.
Identifying all your forked repos
Enter the name of your project (say “oemof” or “pypsa”) in this search bar:
And count how many forked repos are known to Software Heritage (100 entries per screen). You may well find 300 or so forks? Seek your fork to drill down into the details.
Using SWHID persistent identifiers
A very useful feature is each artifact receives a unique persistent identifier called a Software Heritage identifier or SWHID. This is somewhat like a DOI for documents but finer grained. For an overview:
- Software Heritage (ongoing). HOWTO archive and reference your code. Software Heritage. Rocquencourt, France.
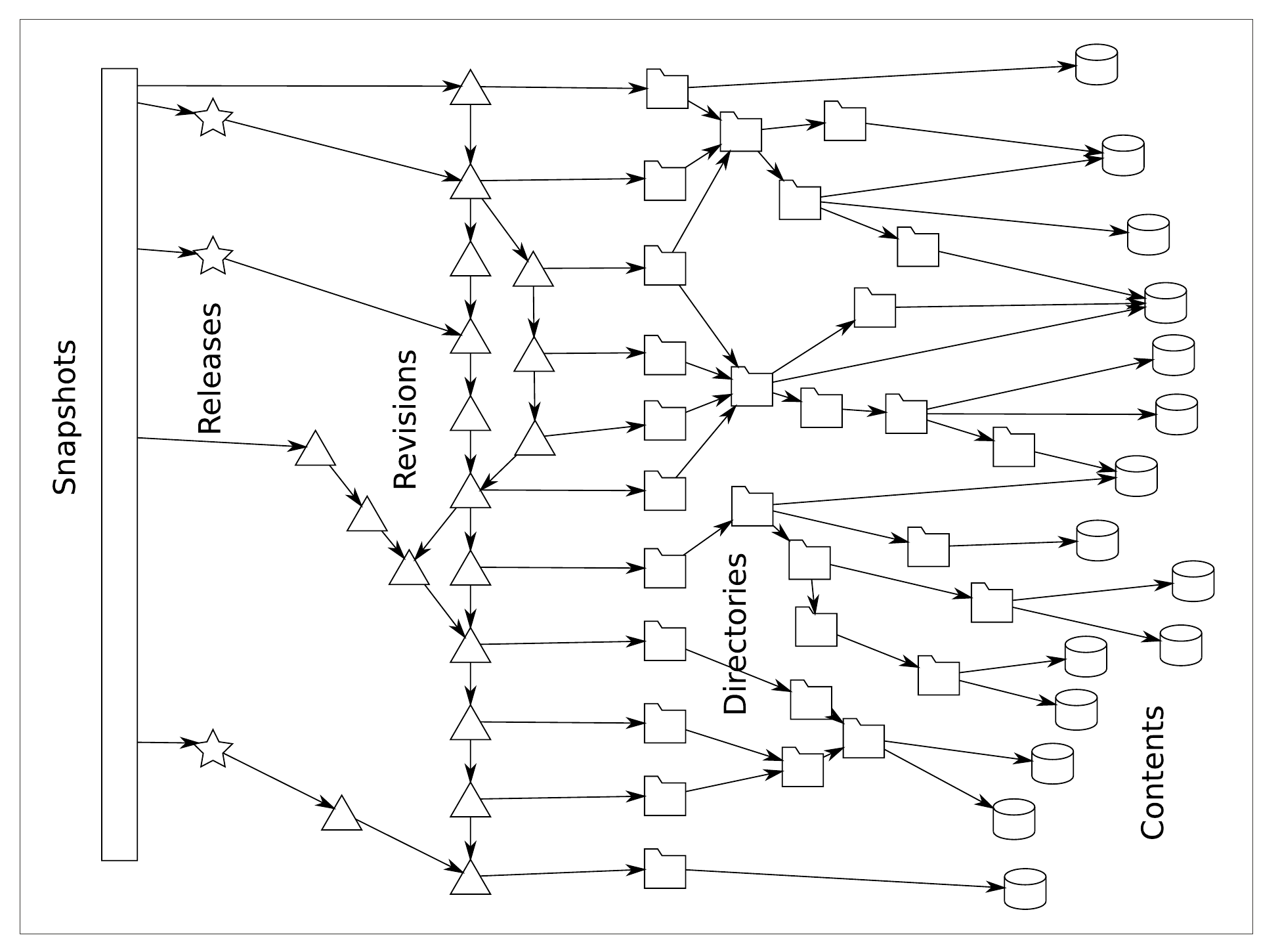
An artifact, also know as an object, can be some kind of content, a directory a revision, a release, or a snapshot. So‑called subparts of objects can be identified, such as a range of lines in a particular source code file.
Here is an example (from Di Cosmo 2020, slide 8):
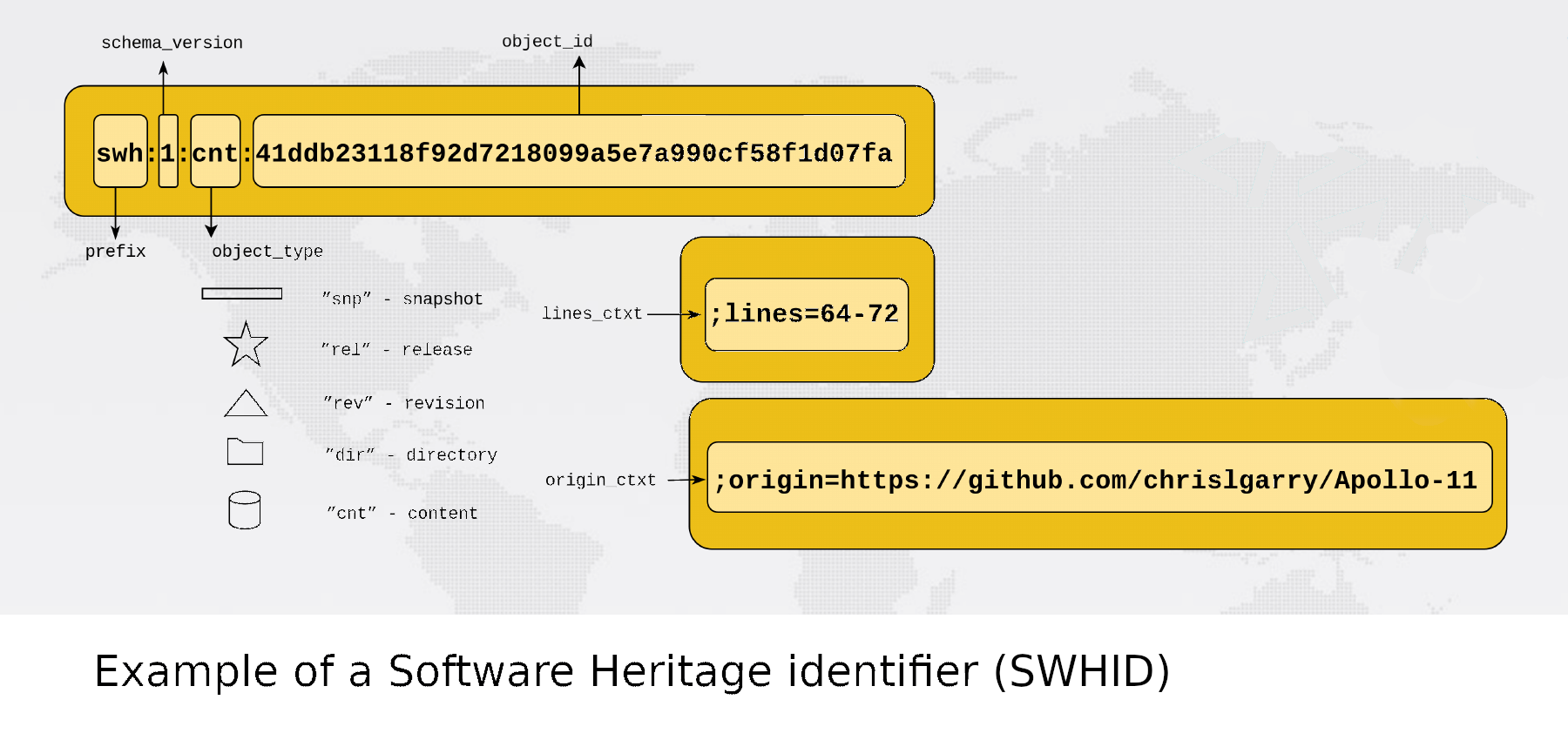
Figure 1: An example of a Software Heritage Identifier (SWHID). The scheme is quite hierarchical as one drills down to the few lines of assembler code that, in this case, ignited the main rocket motor for the Apollo 11 moonshot (harvested from here).
The underlying presentation is this:
- Di Cosmo, Roberto (17 June 2020). Software Heritage: a revolutionary infrastructure for software source code. Presented at OW2online, Paris, France.

The different fields are separated by colons, as indicated in the figure. And the third field indicates the various classes of artifact that can be referred to. There are currently efforts to formalize the SWHID system as a public standard.
Archiving energy systems models
I am talking to Software Heritage about good practice when archiving an energy systems model — a model being a particular codebase instance plus the populating data and usually the raw and interpreted results, generated graphics, and any associated reference scenario. This last point makes things a bit more complicated because a reference scenario is normally a model in its own right. More soon, hopefully.
Additional sources
For in‑depth background, this hour‑long YouTube is worth watching:
- Di Cosmo, Roberto (19 March 2021). Future leader Roberto Di Cosmo on software heritage. London, United Kingdom: OpenUK. YouTube video. Duration 00:56:47.
Closure
I intended to develop this post with additional technical details, when I get the chance.
▢