Which open data license?
RELEASE | 09
This posting can be cited as:
Morrison, Robbie (date of last edit). Which open data license?. Open Energy Modelling Initiative forum. Release 00.
Overview and recommendations
This posting provides some general guidance on the selection of open licenses for datasets arising in the domain of energy systems analysis. Information that could potentially identify an individual is expressly excluded from this discussion. Trade secrets are also excluded. For further background, see Hirth (2020).
The choice of license in this field is normally informed by the overlapping needs of both science and public interest.
A key theme is that while there has been good analysis on what constitutes open data and supportive licensing, too little attention has been paid to questions related to the selection and use of such licenses in their broader context — and specifically that:
- new licenses often claim to be “open” but lack community scrutiny
- legally incompatible but nonetheless technically open licenses will naturally create data silos
- licenses that mandate legal attribution can aid provenance tracking
The resolution advocated here is to settle on the most prevalent community‑approved, attribution‑based data‑capable open license, namely the Creative Commons CC‑BY‑4.0 license.
This strategy does not directly solve the problem of data siloing — but rather opts for a single prevalent silo. The legal requirement to credit contributors should assist with provenance tracking — this feature being of particular significance for information of public interest. And finally, the CC‑BY‑4.0 license has been approved by the accepted license steward (the Open Knowledge Foundation) as complying with the prescribed requirements of the open data community.
Associated metadata, in contrast, should be released under a Creative Commons CC0‑1.0 public domain dedication to facilitate data cataloging with a minimum of friction.
Analysis and advice from researchers and institutions based in the United States regularly fails to account for the more stringent legal protections present in the European Union and United Kingdom. Knowledge of this wider jurisdictional context is therefore needed when appraising such guidance.
The following table summarizes the recommendations offered here — unless a specific use case necessarily indicates some other solution:
| Instrument | Target | Comment |
|---|---|---|
| CC‑BY‑4.0 | canonical or downstream datasets | any associated software needs open source licensing |
| CC0‑1.0 | associated metadata | so as to facilitate cataloging and assist findability |
Other domains may find the material presented here of interest, but should nonetheless confirm that the assumptions used also match their circumstances and objectives.
Non‑personal data
This treatment is necessarily limited to non‑personal data that either can be or has been legitimately published.
What is data in this setting?
Note first that technical perspectives on data and data structures and the definitions provided under intellectual property law can differ substantially. A case in point is the definition of a “database” under European law in which a commercially printed topographic map can legally class as such (Schweizer 2015).
In the context of energy systems analysis and adopting common usage, one can speak of atomic data‑points, standalone and nested datasets, databases with supporting functionality, and domain‑specific data systems. Datasets may span lists, timeseries, tables, and graph structures. The term metadata is taken to be descriptive data added following the acquisition of the primary data to indicate the circumstances of collection and release. Finally, the information under consideration is normally discrete — being single or sampled observations rather than continuous recordings and images.
The Open Knowledge Foundation (OKF) frictionless data scheme allows text‑encoded datasets and metadata in JSON format to be archived in the one file. The frictionless data specification also supports legal information (Frictionless Data ongoing). Several significant projects within the open energy modeling community support this informal data packaging standard (Wiese et al 2019).
The somewhat novel term data system is used here to describe several nascent projects that seek to develop sophisticated domain‑specific data management utilities with comprehensive semantics and complete and coherent content and which also offer integrity assurance, framework-specific export, results capture, and uniform reporting. Some data systems may also interface to canonical datasets using distributed data architectures, including linked open data protocols, to support improved information currency and maintenance (Hellmann 2019, Hoyer‑Klick et al 2021). These various data system projects can perhaps support the currently in vogue notion of digital twinning.
This posting distinguishes between canonical data and downstream data. Canonical data is maintained as a community resource and is corrected and updated as required. Whereas downstream data is downloaded, collated, and/or processed by users in pursuit of some research objective. In sophisticated data management systems, individual data‑points and datasets may also be recalled and reissued automatically. The stack depth is the number of steps removed from the most distant canonical data source. The notions of canonical and downstream data and stack depth are novel but nonetheless useful.
The assessment of renewables potentials, for example, requires high‑resolution geodata and the use of dedicated spatial information databases. This special case is not considered in much detail here, in part because the legal analysis available is limited. Hinz and Bill (2018) provide background on the infrastructure needed but not on licensing.
This posting does not traverse trained artificial intelligence (AI) models and their resulting output which clearly spans both data and code. Current intellectual property law was not designed to cover AI and is clearly struggling in this regard.
Context
This section seeks to narrow the terms of the discussion and provide context and background.
The shortened codes used to indicate various public licenses are known as SPDX identifiers. The more common identifiers, together with their associated license texts, are listed here.
Private information
Private information can be either personal or commercial. Personal information — being information that can potentially be used to identify an individual person — is expressly excluded from this discussion. Commercially private information is covered by the law on trade secrets and thereby precludes material intentionally made public. This posting deals only with non‑personal information that can be or has been legitimately published.
Intellectual property
Two forms of intellectual property may apply to the material under discussion. Datasets can attract traditional copyright protection provided for collective works, also known as compilations. And databases served from within the European Economic Area (EEA) and the United Kingdom may be protected against “substantial” extraction under the 96/9/EC database directive (European Parliament 1996) as transposed into relevant national law (Davidson 2008). In addition, these same databases can also attract copyright if sufficiently creative (Aliprandi 2012).
Note that the legal definition of a 96/9/EC database is far wider than its normal technical definition. And the legal jurisdiction that applies is normally determined by the location of the data server (Husovec 2017).
In essence, the following types of intellectual property right can apply to the data and data structures under discussion:
| Type | Scope of protection | Jurisdictional scope |
|---|---|---|
| copyright for collections | modification and republication | worldwide although national thresholds vary markedly |
| 96/9/EC database right | substantial extraction | European Union (strictly the EEA) and United Kingdom |
It remains far from clear whether datasets that attract copyright but which lack suitable licensing can be numerically processed without infringing copyright.
The public domain
The public domain is a legal doctrine in which a given creative work was either never deemed to be intellectual property or subsequently ceases to be so. The principle reason of interest here is the explicit dedication of material to the public domain by the rights holder. The doctrine of public domain however varies significantly according to the applicable legal jurisdiction. Countries with civil law traditions, like France and Germany, support moral rights, such as the right to attribution, that cannot be fully extinguished by either the creator or the rights holder.
For this reason, the subset of open licenses that act as public domain dedications fall back to maximally permissive open licenses in civil law jurisdictions. Due to these kind of complexities, the use of simple public domain marks (PDM) to signal public domain status is strongly discouraged.
Definitions for open data
A touchstone definition for open data is essential for this debate.
The first clear definition for open data was published by the Open Knowledge Foundation (OKF). The current Open Definition 2.1 states that open data is data that (Open Definition ongoing):
can be freely used, modified, and shared by anyone for any purpose — subject, at most, to measures that preserve provenance and openness
Along similar lines, the more recent European Union open data directive (European Commission 2019) indicates that (recital 16):
open data as a concept is generally understood to denote data in an open format that can be freely used, re‑used and shared by anyone for any purpose
Public licenses
For orientation, public licenses provide users with a set of permissions and obligations beyond the default protections provided by intellectual property law and the law on civil wrongs. One such specified obligation might be the requirement to record and acknowledge previous and present contributors. Public licenses sidestep the need for specifically negotiated bilateral agreements or complicated data brokerage systems and thereby reduce transactional friction markedly. These other systems fall under the rubric of shared data and are not considered further.
Public licenses do not necessarily fulfill the definition for open data as outlined above. For example, the Creative Commons no derivatives (ND) and non‑commercial (NC) attributes render the associated licenses non‑open. That is because these and related restrictions run counter to the open data definitions provided earlier.
Public licenses should not be accompanied by contractual override — a practice whereby users downloading material are required to first consent to additional terms. Such terms may not be enforceable if they remove exceptions provided under copyright law by default.
Open licenses and community approval
Continuing, open licenses are a subset of public licenses that additionally meet community expectations about the attributes of freely usable and reusable information — and in our case the focus is structured information. For most classes of media, there are accepted definitions and accompanying license stewards that approve new licenses. Data is no exception. For data, these are the Open Definition 2.1 (noted earlier) and the Open Knowledge Foundation, respectively.
Open licenses, taken generally, fall into three camps. Public domain waivers (like CC0‑1.0) provide the least obligation on reusers. Attribution licenses (like CC‑BY‑4.0) require that reusers attribute all contributors but are free to incorporate that material into proprietary products without revealing their modifications, for instance. Copy‑left licenses (like CC‑BY‑SA‑4.0) essentially dictate that all outbound material remains under the same licensing, thereby keeping that material within the information commons. Compatibility relationships between commonly encountered licenses of these various types are depicted shortly.
Novel data licenses that have not been scrutinized by the OKF as license steward cannot be considered open — irrespective of claims to the contrary by their proponents. Users should therefore be careful not to create or deploy licenses that have not been thus subject to community scrutiny. Moreover, experience shows that such licenses invariably lack published legal analysis regarding their wider interoperability.
National data licenses
A recent trend for national governments to issue bespoke national licenses is of concern. One example is the German government open data attribution license: dl‑de/by‑2.0. This license is fortunately listed as conformant by the OKF. Bimesdörfe (2019) assesses its interoperability with Creative Commons licenses.
License incompatibility and legal data silos
When datasets under different open licenses are mixed and republished, then the licenses involved will need to be legally compatible and the most restrictive license present necessarily applied to the resulting whole. If obscure but nonetheless technically open licenses are used, this process will naturally lead to data use silos (Lämmerhirt 2017:5) or license fragmentation (Giannopoulou 2018:16). This posting instead adopts the shorter phrase “data silo” to describe the process of limiting reuse through inappropriate license choice.
Jurisdictional issues
Well‑crafted open licenses essentially remove the question of prevailing legal jurisdiction from the right to use and reuse data. In addition, such licenses are now also international and no longer need to be specifically “ported” to align with different national legislation. As indicated, the prevailing law is determined by the location of the server that exposes the information in the first instance.
For completeness, the jurisdictional issues in relation to data reuse approximately resolve to the following questions. Does the public domain exist as a doctrine or are moral rights also in play? Can copyright attach to a collection of data‑points or datasets and under what circumstances? Can databases (as defined in law not practice) be protected against substantial extraction? To what extent and under what circumstances do fair use, fair dealing, and lawfully permitted exceptions necessarily apply? And in what contexts might overarching fundamental rights also be material?
Without traversing the details, this legal spectrum runs from the United States, with a relatively liberal regime for data protection — to the United Kingdom, whereby the thresholds for copyright and database protection are based on mere effort and investment, respectively. Safeguards covering personally identifiable information (PII) also vary by jurisdiction but personal information lies outside the scope of this posting.
Public domain status may well be restricted geographically as well. For instance, work by United States federal employees is only guaranteed to remain public domain within the United States.
Open licenses provide certainty
In many cases, the kind of datasets under discussion are not protected under law, particularly in more liberal originating jurisdiction (such as the United States, for instance). But in more stringent jurisdictions, that certainty may not apply (the United Kingdom, for instance) and open licenses naturally provide users with legal certainty. In addition, information moved across jurisdictions may inadvertently attract new protections. In which case, the following maxim can apply:
open data licenses may not necessarily grant new legal permissions but they do explicitly provide for legal certainty
If one adds an open license to material that is not protected by copyright (anywhere in the world) or 96/9/EC database rights (the EEA and the UK only), then no particular harm is done and that license can be technically ignored — because there are no underpinning rights to license.
Conversely, if one publishes a dataset without an open license, then its legal status depends on the applicable legal jurisdiction and its creative attributes, if any. Moreover if that dataset is published from a database system hosted within the EEA or the UK and the extraction is “substantial”, then 96/9/EC database rights held by the database provider may well be infringed. The concept of substantial in this context cannot be evaluated by users and database providers can strategically “subdivide” their databases in order to lower the bar for substantial extraction (Davidson 2008).
Intellectual property law is not necessarily the only legal doctrine in play (Davidson 2008, Husovec 2017). Civil law constructs like misappropriation and related quasi‑property rights may apply. These additional factors are nonetheless also erased by the application of well‑crafted open licenses.
Data standards
Collected data is normally subject to higher level standards covering semantics, formats, metadata requirements, and so forth. If those standards are genuinely open then legal problems cannot arise. But if those standards are proprietary, compliant datasets could class as derivative works and become legally encumbered. This suggestion is speculative and there is no literature exploring such issues.
Licensing options for open data
This section discusses individual licenses and the reasons for their consideration and selection here.
Regarding terminology, the word “license” is used to cover “waivers” and “dedications”, unless the context would indicate otherwise. In relation to scope, as indicated, information that can identify individuals is excluded from this discussion. And metadata, usually added following primary collection, should always be licensed CC0‑1.0 in order to place the least overhead on cataloging and indexing services provided by third parties.
The term “use” covers the action of downloading and utilizing a dataset or similar. The term “reuse” (also styled “re‑use”) covers the action of publishing a dataset or similar and allowing other parties to utilize it. This latter treatment diverges from the legal definition provided in European directive 2019/1024 §2.11, as discussed later.
The term “open access data” should now never be used to indicate open data. Open access, under its weakest definition, means available for download but with all legal protections in place and silent on how any 96/9/EC database rights should be handled in those jurisdictions where those rights can attach.
Open licenses under consideration
For reasons discussed elsewhere, just two licenses are being considered in this posting:
| License | Type | Comment |
|---|---|---|
| CC‑BY‑4.0 | attribution license | mandatory attribution can contribute to provenance tracking |
| CC0‑1.0 | public domain dedication | places least obligations on users, always recommended for metadata |
The following instruments were rejected from further consideration: Creative Commons CC‑PDDC and CC‑BY‑SA‑4.0, Open Knowledge Foundation (OKF) Open Data Commons PDDL‑1.0, ODC‑By‑1.0, and ODbL‑1.0, Linux Foundation CDLA‑Permissive‑2.0 and CDLA‑Sharing‑1.0, and open government licenses like the OGL‑UK‑3.0 and the German DL‑DE‑BY‑2.0. Public domain marks confer nothing and may well be misleading where the public domain status is nationally limited. The use of share‑alike licenses for open data, which often implicitly precludes commercial usage, has fallen from favor. The OKF has effectively deprecated its own ODC instruments for reasons of legal siloing (Lämmerhirt 2017). The Linux Foundation CDLA licenses have not been subject to approval by the recognized license steward and may well indeed not even class as open. Nor have their interoperability or otherwise with Creative Commons licenses by independently established. And national government data licenses are often legally restricted to official usage. They may also specify the choice of law for litigation.
Individual data‑capable open licenses are analyzed comparatively by Ball (2014), Giannopoulou (2018), and the supplementary material to Hirth (2020).
The ScanCode LicenseDB project archives public licenses for software and data found “in the wild” to support automated license scanning. That database currently contains about 17 000 entries.
The CC0‑1.0 public domain dedication falls back to a maximally permissive open license in civil law jurisdictions (such as Germany), as discussed earlier.
The attribution stack claim
There is a long‑running debate about whether legal attribution is a help or a hindrance. Or restated in this context of this posting, should the CC‑BY‑4.0 open license or CC0‑1.0 public domain dedication be favored for open datasets and databases. And sitting immediately behind this dilemma is the so‑called “attribution stack” problem.
The attribution stack refers to the depth of attribution required as datasets are repeatedly merged and modified to form new datasets and then republished. The argument is that the overhead of handling the ever increasing amounts of contributor metadata will become unwieldy to the point of impractical (the scaling is often said to be exponential but it is mathematically unlikely that the big O complexity is that extreme).
The attribution stack problem has to be confronted irrespective unless one opts to work solely with material that is unquestionably public domain or subject to explicit public domain waiver (such as the CC0‑1.0).
It is also questionable whether the repeated reworking of data in this manner is good practice. Another perspective is that interacting back “upstream” should be the norm and that the stack depth should best never exceed about four or so hops. Indeed, corrections or improvements should be passed back up to the canonical datasets that a particular domain maintains collectively. Furthermore, new found faulty data might even be subject to automatic recall and reissue. This approach therefore requires cooperation and discipline.
Energy sector data
It is virtually unheard of for entities within the energy sector in Europe and the United Kingdom to release their published information under CC0‑1.0. Several organizations do voluntarily release information however (the French transmission system operator RTE being one example) but only under instruments that are inbound compatible with the CC‑BY‑4.0 alone. The United Kingdom energy sector regulator Ofgem is looking at open licensing at the moment, but again CC‑BY‑4.0 (Ofgem 2021). The German network regulator BNetzA uses CC‑BY‑4.0. The European Commission favors CC‑BY‑4.0 for the reuse of Commission data‑centric documents (by my reading of Gentile et al 2019:13).
Much of the information that energy system analysts rely on is under some form of statutory reporting. That reporting is split in Europe into energy system information and wholesale energy market information. One might expect the legal status of the resulting datasets to be resolved but, sadly, the underpinning legislation that mandated publication was silent on licensing.
Indeed, energy market data under statutory reporting within Europe is deliberately served using techniques to prevent its numerical recovery — a practice that clearly runs counter to the spirit of statutory reporting even if technically compliant. Indeed ACER has confirmed these practices are compliant.
Electricity system data within Europe is collected and served from the ENTSO‑E Transparency Platform. While this information is readily available, its legal status for reuse remains unsettled. The open energy modeling community has been working with ENTSO‑E to improve the situation but progress requires unanimous agreement from all parties submitting primary data. Legal uncertainty has not, however, prevented the Washington‑based World Resources Institute (WRI) from harvesting datasets from the Transparency Platform and republishing them on their PowerExplorer portal under CC‑BY‑4.0 licensing. This particular practice also adds another hop to the stack depth.
It is also worth emphasizing what bad shape much of the information under statutory reporting is in. In Europe, the OPSD project (with around one million euro in funding) uses community curation to clean up energy sector information published mostly under statutory reporting (Wiese et al 2019). Even conceptually simple tasks like compiling a list of conventional power plant assets located within Europe is problematic — despite these items being substantial and long‑lived (Gotzens et al 2019) (more on that topic here as well).
Problematic licenses
There are a number of licenses, some prominent, that are presumed open but have not been subject to oversight by the Open Knowledge Foundation in its role as the licensing steward for the open data community. The concept of license stewardship is well established within the open source software community, where that role falls mostly to the Open Source Initiative (OSI). The following example illustrates the kind of issues raised by unaccredited license development within the energy sector.
By way of example, in December 2020, the United Kingdom‑based electricity distributor Western Power Distribution (WPD) released a data license based on the UK Government OGL‑UK‑3.0 license but with three lines altered. This exercise provides a case study on how not to open license data. That particular license is now databased (GitHub diff) by the ScanCode Project (cited earlier) with the SPDX identifier scancode‑ogl‑wpd‑3.0 so that it can now be recognized and reacted to in the wild. To the author’s knowledge, the license text itself has not been subject to published legal analysis, nor has it been approved by the acknowledged license steward. Moreover, the license will almost certainly create a new data silo in practice and one not miscible with CC‑BY‑4.0 licensed material. And while there is absolutely no suggestion that WPD intended to limit the usefulness of the information it publishes, the net effect is nonetheless precisely that.
Wikidata project
The Wikidata project is part of the Wikipedia family. As technical as it may seem, the Wikidata project is not canonical and may well have benefited from being at least part‑licensed under CC‑BY‑4.0 and not CC0‑1.0. Indeed CC‑BY‑4.0 licensing provides the maximum inbound possibilities for information.
Literature review
This section reviews various viewpoints on the topic of data licensing in chronological order. This history is naturally bisected by the release of the Creative Commons CC‑BY‑4.0 license in November 2013.
Wilbanks (2008) and Murry‑Rust (2008) both argue clearly for public domain dedications to be applied to data.
Conversely, de Rosnay (2010) speculates on the motivation for using attribution licenses generally (p 28):
Beyond fame and pride, it is a common feeling among creators to share their creation only in exchange of public recognition — and perhaps more visibility on their other activities.
Aliprandi (2012) covers the open licensing of databases in the context of 96/9/EC database rights. Aliprandi and Piana (2013) recommend the use of CC0‑1.0 dedication by public administrations within Europe.
Creative Commons releases the CC‑BY‑4.0 license during November of 2013 — this being the first data‑capable attribution type license. It is also international, so the one license text is applicable in all jurisdictions.
Ball (2014) reviews commonly encountered data‑capable licenses and describes their application, but does not back any particular license or licensing strategy.
Doldirina et al (2016) clearly recommends CC0‑1.0 or PDDL‑1.0 dedications in order to build a global research data commons with minimum friction.
Lee (2016) surveys the legal issues concerning the open licensing of government data — equivalent to public sector information insofar that just data is involved — across a number of jurisdictions. Lee opines that applying CC‑BY‑4.0 licenses to material clearly not protected by law can be contentious — although jurisdictions with 96/9/EC database protection naturally fall outside that scope of certainty (p 211). Moreover, Lee views the difference between CC‑BY‑4.0 and CC0‑1.0 as small, noting that (p 235):
Some commentators view these attribution‑only licenses as “quasi‑public domain dedications”.
Su (2016) argues for CC0‑1.0 dedications and points specifically to interoperability with the Wikidata project. Wikidata has opted for CC0‑1.0 for maximum outbound flexibility over maximum inbound flexibility (Wikidata licensing). The merits of this license choice for non‑canonical data were discussed earlier.
Oxenham (2016) documents his difficulties in obtaining suitable license notices for third‑party academic datasets prior to publication.
Lämmerhirt (2017), writing for the Open Knowledge Foundation (OKF), fails to mention the ODC‑By‑1.0 and ODbL‑1.0 licenses, so one can only assume that the OKF has implicitly deprecated their own two dedicated data‑capable instruments.
Giannopoulou (2018) provides an excellent summary (the best I have read) of the legal landscape for open data. She covers the merits of all commonly encountered data‑capable open licenses, their interoperability (or “licensing matrix”), and their siloing effect (or “fragmentation”). She argues that a legal requirement to attribute is indeed beneficial (p 121):
The attribution requirement is an important element of open data, whether as part of the license restrictions or as part of a contractual limitation on top of a waiver. It constitutes a restriction justified by open data policies since it contributes to the policy justifications of transparency. In this respect, attributing the source of the data used could be qualified as one of the most common restrictions imposed among many open data policies applied.
That passage appears to be a call for CC‑BY‑4.0, given that no other widely‑used data‑capable attribution license is inbound or outbound compatible in practice. Indeed, it is better to converge on a widely‑used silo, if one must indeed create legal silos. Moreover Giannopoulou argues the CC0‑1.0 dedication has downsides in terms of open data (p 112):
However, the use of CC0 did not necessarily ensure respect of the principles of open data. For example, the free use of data did not accommodate the conditions of attribution and provenance in the use of databases.
Giannopoulou also suggests that 96/9/EC database rights cannot apply to public sector information and either indicates or reviews legislation and case law from France, Germany, Italy, and the Netherlands on this matter (p 106). (I have long argued, based on recital 41 of the database directive, that the same should apply to information served under statutory reporting. More later too on the CJEU case C‑762/19 in 2021.)
Carbon et al (2019) survey license use in the biomedical area and find three CC0‑1.0 dedications and eight CC‑BY‑4.0 licenses present (full table).
Margoni and Tsiavos (2019) specifically examine open science in a European context and recommend CC0‑1.0 licensing for scientific data. One rationale is that intellectual property might not apply and that it is better to request recognition than attempt to demand attribution via not‑necessarily-enforceable legal terms. The authors also indicate that their advice may need to change as developments progress. Their treatment of database rights is unlikely to be correct. (Not directly relevant here but the suggestion by Margoni and Tsiavos on page 11 that CC‑BY‑4.0 is usually the best choice for software in quite simply wrong.)
The OpenAIRE project recommendations on data licensing, as underpinned by Margoni and Tsiavos (2019) and summarized here, should be disregarded due to analytical limitations in the underlying inquiry.
Grabus and Greenberg (2019) provide a useful review of issues beyond licensing, including community norms and standards, but do not offer a position on the attribution debate.
Hirth (2020) observes that electricity sector data under mandatory publishing remains legally encumbered by default and furthermore that users are often not aware of who the rightsholder might be. Hirth prefers CC0‑1.0 with CC‑BY‑4.0 as a good alternative. Hirth also points out that infringing intellectual property rights in Germany can be a criminal matter.
The U4RIA project, aimed at strengthening energy policy analysis in the global south, is committed to CC‑BY‑4.0 licensing (Howells et al 2021).
License compatibilities
License compatibilities can be depicted as a directed acyclic graph (DAG). An arrow spanning two licenses indicates that material under the originating license is “inbound compatible” with material under the receiving license. These restricted legal compatibilities, together with community practices at large, give rise to the so‑called data silos that are central to much of the discussion here.
The question of license compatibility technically only arises for data‑points and datasets that are mixed. It would be perfectly acceptable to publish a collection of datasets, each under a different open license, with the proviso that the compilation itself should also be explicitly open licensed. That said, such practice would doubtless result in widespread confusion.
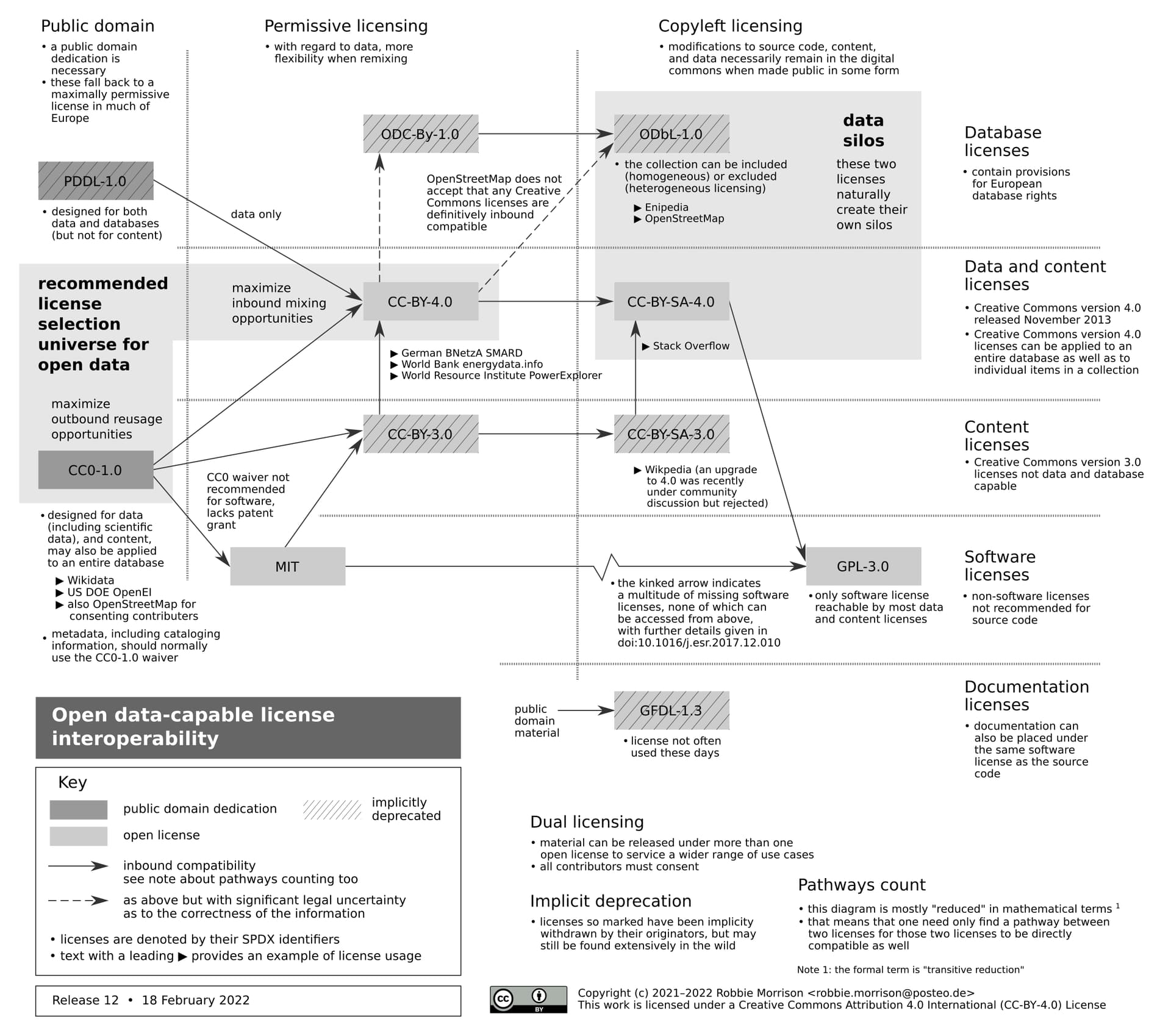
Figure 1: Open data‑capable license interoperability. The doi:10.1016/j.esr.2017.12.010 indicated in the diagram is listed here as Morrison (2018). There are just two licenses in the license selection universe that warrant consideration, as indicated.
The European Commission offer a web‑based license selection utility named Joinup (Schmitz and Cacciaguerra Ranghieri 2018). Having looked around, this author is not remotely convinced of its accuracy or veracity.
Litigation
As of December 2022, the Gesellschaft für Freiheitsrechte (GFF) is counter‑suing the state of Bavaria in a case involving the ability to access, use, and republish information of public interest (GFF 2022). See here for details.
One clear point is that local and national governments will litigate if they believe their revenue model is being undermined by users who treat their information as public domain.
Analysis
First, to reiterate that data that could potentially identify a person is not considered in this posting. Nor is commercially sensitive information covered, beyond that mandated under statutory reporting or provided voluntarily.
There are two distinct threads in the literature concerning open data: one centers on scientific research and the other on public interest information provision. All things considered, those advising on open science tend to favor CC0‑1.0 dedications while those advocating for open public information provision tend to favor CC‑BY‑4.0 licensing. That said, any arbitrary line between these two camps is progressively softening — for instance, climate data now self‑evidently spans both science and public interest (ODC work‑in‑progress).
Legal jurisdiction may also play a significant role. Several of those cited as favoring public domain dedications, including Wilbanks and Su, are based in the United States. And this may well make the difference because data from United States federal employees is also public domain within that country — unlike the Europe Union where public sector information under open data provisions is more likely to be subject to CC‑BY‑4.0 licensing. Moreover, scientific datasets in the United States are less likely to attract any form of intellectual property protection due to a materially different threshold for copyright and no explicit protection for databases (US Copyright Office 2017).
And while there are clearly advocates for share‑alike licensing in the data community, usually opting for the Open Data Commons ODbL‑1.0 license, there appears to be no equivalent support in the published literature.
One use‑case where CC0‑1.0 licensing is indicated is where those publishing a dataset have had no real connection with its collection and preparation (decorum prevents me from citing examples).
The Wikidata project has opted to use the CC0‑1.0 public domain dedications by policy. This may work well enough for material originating within the United States context but will clearly cause difficulties for inbound material originating from the European Union and United Kingdom, which is often under stronger licensing.
Another special case are projects that leverage from OpenStreetMap (OSM). OSM is licensed under the ODbL‑1.0 share‑alike data license. It is understood that secondary projects, built over OSM, can be licensed using CC‑BY‑4.0, which then circumvents the lack of interoperability that ODbL‑1.0 licensing necessarily entails. Moreover the author could not locate legal analysis on the open licensing of spatial information in general.
Several of the authors reviewed earlier suggest (as does much of the open source software world) that open licenses are as much prompts for community norms as they are legal instruments. That view would also serve as a counter to the arguments put forward by Margoni and Tsiavos (2019) against CC‑BY‑4.0 licensing.
It would be a mistake to treat legal attribution and metadata management as orthogonal questions. They are clearly not and treating metadata properly will naturally sweep up any legal obligations to attribute. Ball (2020:4) covers this point under the rubric of “restrictions” on data use as conveyed by metadata. Moreover, the automated processing of legal metadata (and other metadata) is likely to become standard practice within sophisticated data communities.
For comparison, open source software stacks, which typically embed complex dependencies and a good number of different licenses, are now scrutinized using advanced license compliance tooling. But with good data management, the equivalent challenge should never arise. The analogous attribution stack problem is arguably related to a lack of sophistication. Indeed, energy system analysts are starting to experiment with distributed data architectures and linked open data more specifically. These new schemes are designed to give ready access to the canonical datasets and may well support smart features like automated recall and reissue in due course. The technical details involved are beyond the scope of this posting. But worth noting such schemes are technically fragile under current circumstances.
It is useful to emphasize that open data is a much deeper social exercise than open numerics. One can see this clearly in the domain of energy systems analysis where any number of individual and somewhat idiosyncratic modeling projects can and do happily coexist — but data requires a domain‑wide consensus on the high‑level constructs of semantics, metadata, and collection standards — and, to a lesser extent, on technical and architectural data conventions. It is easy to dub this nascent entirety as an “ecosystem” and then not fully recognize the difficult and skilled work required for its establishment and maintenance.
There are some additional considerations for public sector information and information under statutory reporting that were not traversed earlier due to a limited literature. It is quite probable, for instance, that 96/9/EC database protection would not apply to datasets provided under statutory reporting, but there is neither case law nor unequivocal legal analysis on that matter (Giannopoulou 2018).
A seminal ruling in 2021 from the Court of Justice of the European Union (CJEU) limited the protection offered by the 96/9/EC database directive under case C‑762/19 (CJEU 2021). For a substantial extraction to be legally actionable, the database operator must now be exposed to genuine commercial risk, such that: “those [third party] acts adversely ffect [the database maker’s] investment in the obtaining, verification or presentation of that content, namely that they constitute a risk to the possibility of redeeming that investment through the normal operation of the database in question” (direct quote from ruling).
Bond (2021) opines that while this CJEU ruling applies solely to a case involving a specialist search engine, the CJEU’s “reasoning has potentially profound implications for the enforcement of database rights in other contexts”. And further, that “the reasoning that an infringement only occurs where there is a risk to the possibility of the maker redeeming their investment would appear to be a general principle capable of application to any situation involving infringement of database rights”.
It would therefore seem unlikely that a research institute lacking third‑party funding could explicitly claim 96/9/EC database projection for an online database serving IPCC‑related information (decorum again prevents me for naming that institution).
Most countries offer fair use or fair dealing provisions or lawfully permitted exceptions to cover the scientific use of protected material. While these mechanisms can be useful, they significantly limit potential use cases, need to be specifically evaluated for every circumstance, and fall well short of any notion of generalized open data.
For completeness, fundamental rights, such as academic freedom, may also apply. But one may well face litigation to defend the the merits of one’s particular circumstances in this context (Caspers 2016).
The European Union definition of “reuse” as mere “use” contained in the open data directive (§2.11 in European Commission 2019) is likely to be highly problematic should litigation arise. European lawmakers should fix this perverse definition as a matter of priority.
That open data directive definition is encompassed by the notion of copyright verbs, which duly provide information on what third parties may do with protected material. Copyright verbs, as such, are a well‑established legal concept (Smith no date, Rosen 2007, Higgs and Gutsche 2021). Taken from official documents within Europe, copyright (and allied rights) verbs include: use, share, reuse, extract, and re‑utilize. Yet the open data directive 2019/1024 provides recipients only with “use”. I argue that this copyright verb offers no more rights in this respect than that provided by default under copyright law in the context of normal access.
The open data directive definition of a “public sector body”, which removes 96/9/EC database protection, does not include industry bodies operating under legal mandate, such as ENTSO‑E (as confirmed by the legal department at ENTSO‑E).
Research data from universities is also now covered under the 2019 open data directive (van Eechoud 2021) — but these provisions are not sufficiently broad to class as open data and thereby be available to non‑scientists.
Discussion
In many respects, the concept of open data now prevails but material issues surrounding license selection have remained sidelined. Now would be a good time to broaden that debate and resolve the twin questions of legal interoperability and data provenance that licensing recommendations necessarily entail.
The choice between public domain dedication and attribution licensing was once seen as essentially a trade‑off between friction and provenance. But as data management becomes rapidly more sophisticated within open science, community support for explicit attribution will doubtless replace concerns about the overhead of tracking contributors. That shift would better represent both the needs and ethos of scientific research. Indeed, those stressing the attribution stack problem implicitly invoke an outmoded paradigm for data management — one now being rapidly replaced by advances in distributed data architectures which necessarily limit the stack depth.
As argued here and in the absence of specialist considerations, CC‑BY‑4.0 licensing should be generally favored for datasets and databases and CC0‑1.0 licensing for associated metadata.
The voluntary open licensing of public sector data, while workable enough, would be better replaced by legislative reform covering the default conditions under which public interest data and information under statutory reporting is made available.
Going further, the European Union should repeal the 1996 database directive — this novel intellectual property right has failed to remotely fulfill its intended objective to support a “database industry” and never become universal. And, as the Transparency Platform/PowerExplorer example indicates, European information simply ends up being harvested and served from infrastructure located elsewhere.
If the 96/9/EC database directive cannot be repealed, that property right should be treated like a patent and subject to filing, examination, approval, and periodic maintenance fees.
France assumed the European Union presidency in 2022 and has announced the development of a “digital commons” as a priority. Perhaps the multitude of data licensing problems raised here will be resolved as part of that process.
One final plea to those providing professional advice on open data licensing. Licensing policy and license selection must be guided by the intricacies of data management and legal administration as encountered in practice. It is otherwise all too easy to contribute to the ever growing pileup on the information Autobahn with well meaning but deficient instructions.
References
Aliprandi, Simone (March 2012). “Open licensing and databases”. International Free and Open Source Software Law Review. 4 (1): 5–18. ISSN 1877‑6922. doi:10.5033/ifosslr.v4i1.62. CC‑BY‑ND‑2.0 license.
Aliprandi, Simone and Carlo Piana (28 March 2013). “FOSS in the Italian public administration: fundamental law principles”. International Free and Open Source Software Law Review. 5 (1): 43–50. ISSN 1877‑6922. doi:10.5033/ifosslr.v5i1.84. CC‑BY‑ND‑2.0 license.
Ball, Alex (17 July 2014). How to license research data. Edinburgh, United Kingdom: Digital Curation Centre (DCC).
Ball, Alex (9 October 2020). Towards a metadata Rosetta Stone: the RDA MIG metadata element — Presentation. Bath, United Kingdom: University of Bath. MIG is metadata interest group.
Bond, Toby (21 July 2021). CV-Online Latvia: CJEU complicates the enforcement of database rights. Bird and Bird. London, United Kingdom. Legal blog.
Booshehri, Meisam, Lukas Emele, Simon Flügel, Hannah Förster, Johannes Frey, Ulrich Frey, Martin Glauer, Janna Hastings, Christian Hofmann, Carsten Hoyer‑Klick, Ludwig Hülk, Anna Kleinau, Kevin Knosala, Leander Kotzur, Patrick Kuckertz, Till Mossakowski, Christoph Muschner, Fabian Neuhaus, Michaja Pehl, Martin Robinius, Vera Sehn, and Mirjam Stappel (27 April 2021). “Introducing the Open Energy Ontology: enhancing data interpretation and interfacing in energy systems analysis”. Energy and AI. 100074. ISSN 2666‑5468. doi:10.1016/j.egyai.2021.100074. Journal pre‑proof.
Bimesdörfe, Kathrin (editor) (February 2019). Datenlizenzen für Open Government Data: Rechtliches Kurzgutachten: Handreichung zu den Nutzungsrechteregelungen gebräuchlicher Open Data Lizenzen und Empfehlungen für ihren Einsatz [Data licenses for Open Government Data: Legal brief: Guidance on the usage rights of common open data licenses and recommendations for their use] (in German). Düsseldorf, Germany: Ministerium für Wirtschaft, Innovation, Digitalisierung und Energie des Landes Nordrhein‑Westfalen.
Carbon, Seth, Robin Champieux, Julie A McMurry, Lilly Winfree, Letisha R Wyatt, and Melissa A Haendel (27 March 2019). “An analysis and metric of reusable data licensing practices for biomedical resources”. PLOS ONE. 14 (3): –0213090. ISSN 1932‑6203. doi:10.1371/journal.pone.0213090.
Caspers, Marco (20 January 2016). The role of Anne Frank’s diary and academic freedom for text and data mining. Kluwer Copyright Blog. Alphen aan den Rijn, the Netherlands.
CJEU (3 June 2021). Judgment of the Court on ‘CV-Online Latvia’ SIA v ‘Melons’ SIA, case C‑762/19, document ECLI:EU:C:2021:434. Luxembourg City, Luxembourg: Court of Justice of the European Union (CJEU). 6 pages.
Davidson, Mark J (January 2008). The legal protection of databases. Cambridge, United Kingdom: Cambridge University Press. ISBN 978‑0‑521‑04945‑0. Paperback edition.
de Rosnay, Melanie Dulong (20 December 2010). Creative Commons licenses legal pitfalls: incompatibilities and solutions — Version 1.1. Amsterdam, the Netherlands: Institute for Information Law, University of Amsterdam. Report. Archived at halshs‑00671622.
Doldirina, Catherine, Anita R Eisenstadt, Harlan Onsrud, and Paul F Uhlir (12 August 2016). Legal approaches for open access to research data. LawArXiv preprint.
European Commission (24 July 2014). “Commission notice: guidelines on recommended standard licences, datasets and charging for the reuse of documents”. Official Journal of the European Union. C 240: 1–10.
European Commission (December 2017). Legal opinion: legal aspects of European energy data — Output 2 of the “Study on the quality of electricity market data”. Brussels, Belgium: European Commission. Prepared with the help of Till Jaeger.
European Commission (26 June 2019). “Directive (EU) 2019/1024 of the European Parliament and of the Council of 20 June 2019 on open data and the re‑use of public sector information — PE/28/2019/REV/1”. Official Journal of the European Union. L 172: 56–83.
European Commission (19 February 2020). Communication from the Commission to the European Parliament, the Council, the European Economic and Social Committee and the Committee of the Regions: a European strategy for data — COM (2020) 66 final. Brussels, Belgium: European Commission. Includes a common European energy data space.
European Parliament and European Council (27 March 1996). “Directive 96/9/EC of the European Parliament and of the Council of 11 March 1996 on the legal protection of databases”. Official Journal of the European Union. L 77: 20–28.
Frictionless Data (ongoing). Applying licenses, waivers or public domain marks. Frictionless data. Cambridge, United Kingdom. Mostly written by Stephen Gates.
Gentile, Stefano, Ines Georgieva, Maria Iglesias, Pedro Malaquias, and Jean Paul Triaille (2019). Reuse policy: a study on available reuse implementing instruments and licensing considerations — EUR 29685 EN. Luxembourg: Publications Office of the European Union. ISBN 978‑92‑76‑00670‑1. doi:10.2760/95373. JRC115947.
GFF (9 December 2022). GFF klagt mit Datenjournalist gegen den Freistaat Bayern: Urheberrecht darf nicht missbraucht werden, um Pressefreiheit einzuschränken [GFF files suit with data journalist against the Free State of Bavaria: copyright must not be abused to restrict freedom of the press] (in German). GFF – Gesellschaft für Freiheitsrechte e.V.
Giannopoulou, Alexandra (2018). Chapter 6: Understanding open data regulation: an analysis of the licensing landscape. In Bastiaan van Loenen, Glenn Vancauwenberghe, and Joep Crompvoets (editors) (2018). Open data exposed. The Hague, the Netherlands: TMC Asser Press. ISBN 978‑94‑6265‑261‑3. doi:10.1007/978‑94‑6265‑261‑3_6.
Gotzens, Fabian, Heidi Heinrichs, Jonas Hörsch, and Fabian Hofmann (1 January 2019). “Performing energy modelling exercises in a transparent way: the issue of data quality in power plant databases”. Energy Strategy Reviews. 23: 1–12. ISSN 2211‑467X. doi:10.1016/j.esr.2018.11.004.
Grabus, Sam and Jane Greenberg (4 July 2019). “The landscape of rights and licensing initiatives for data sharing”. Data Science Journal. 18 (1): 29. ISSN 1683‑1470. doi:10.5334/dsj‑2019‑029.
Hellmann, Sebastian (29 September 2019). DBpedia’s Databus and strategic initiative to facilitate “1 billion derived knowledge graphs by and for consumers” until 2025. Leipzig, Germany: DBpedia.
Higgs, Daphne and Pete Gutsche (29 September 2021). Show me the money: monetizing IP via licenses — Presentation. Washington, USA: Perkins Coie LLP.
Hinz, Matthias and Ralf Bill (2018). Mapping the landscape of open geodata. 21th AGILE Conference on Geographic Information Science.
Hirth, Lion, Ingmar Schlecht, and Jonathan Mühlenpfordt (6 November 2018). Open data for electricity modeling: an assessment of input data for modeling the European electricity system regarding legal and technical usability — White paper. Berlin, Germany: Neon Neue Energieökonomik. A report for the Federal Ministry for Economic Affairs and Energy, Germany.
Hirth, Lion (1 January 2020). “Open data for electricity modeling: legal aspects”. Energy Strategy Reviews. 27: 100433. ISSN 2211‑467X. doi:10.1016/j.esr.2019.100433. Open access.
Howells, Mark, Jairo Quiros‑Tortos, Robbie Morrison, Holger Rogner, Taco Niet, Luca Petrarulo, Will Usher, William Blyth, Guido Godínez, Luis F Victor, Jam Angulo, Franziska Bock, Eunice Ramos, Francesco Gardumi, Ludwig Hülk, Patrick Van‑Hove, Estathios Peteves, Felipe de Leon, Andrea Meza, Thomas Alfstad, Constantinos Taliotis, George Partasides, Nicolina Lindblad, Benjamin Stewart, and Ashish Shrestha. (10 March 2021). Energy system analytics and good governance — U4RIA goals of Energy Modelling for Policy Support — Preprint. doi:10.21203/rs.3.rs‑311311/v1.
Hoyer‑Klick, Carsten, Johannes Frey, Ulrich Frey, Hedda Gardian, Anastasis Giannousakis, Jan Göpfert, Tobias Hecking, Christian Hofmann, Sophie Jentzsch, Kevin Knosala, Leander Kotzur, Stefan Kronshage, Patrick Kuckertz, Christoph Muschner, Michaja Pehl, Vera Sehn, and Detlef Stolten (28 October 2021). Implementing FAIR through a distributed data infrastructure. Germany: DLR et al. Parallel session presentation to EMP‑E 2021 online conference, 28 October 2021, 14:00–15:30 CEST.
Husovec, Martin (November 2017). Injunctions against intermediaries in the European Union: accountable but not liable. Cambridge, United Kingdom: Cambridge University Press. ISBN 978‑1‑108‑41506‑4. doi:10.1017/9781108227421.
Lee, Jyh‑An (2017). “Licensing open government data”. Hastings Business Law Journal. 13 (2): 207–240.
Lämmerhirt, Danny (December 2017). Avoiding data use silos: how governments can simplify the open licensing landscape. Open Knowledge International. Cambridge, United Kingdom.
Margoni, Thomas and Prodromos Tsiavos (January 2019). Toolkit for researchers on legal issues — D3.2 – Version 1.0 – Final. OpenAIRE. doi:10.5281/zenodo.2574618.
Morrison, Robbie (April 2018). “Energy system modeling: public transparency, scientific reproducibility, and open development”. Energy Strategy Reviews. 20: 49–63. ISSN 2211‑467X. doi:10.1016/j.esr.2017.12.010. Open access. CC‑BY‑4.0 license.
Mozilla (ongoing). License stacking. Mozilla Science Lab’s open data primers.
Murray‑Rust, Peter (18 January 2008). “Open data in science”. Nature Precedings. ISSN 1756‑0357. doi:10.1038/npre.2008.1526.1.
ODC (work‑in‑progress). Open up climate data: using open data to advance climate action — Draft. International Open Data Charter. Accessed 16 April 2021. Not to be confused with the Open Data Commons.
Ofgem (15 November 2021). Decision on Data Best Practice Guidance and Digitalisation Strategy and Action Plan Guidance. London, United Kingdom: Office of Gas and Electricity Markets (Ofgem). OGL‑UK‑3.0 license.
Open Definition (ongoing). Conformant licenses — Open definition — Defining open in open data, open content and open knowledge. Open Definition. Oxford, United Kingdom.
Open Definition (ongoing). Guide to open data licensing — Open definition — Defining open in open data, open content and open knowledge — Version 1.1. Open Definition. Oxford, United Kingdom.
Oxenham, Simon (4 August 2016). “Legal confusion threatens to slow data science”. Nature. 536: 16–17. ISSN 0028‑0836. doi:10.1038/536016a.
Pollock, Rufus (9 February 2009). Comments on the Science Commons protocol for implementing open access data. Open Knowledge International Blog.
Rosen, Lawrence (2007). OSL 3.0 explained. Rosenlaw and Einschlag. California, USA.
Salazar, Krystle (3 December 2020). Explore the new CC legal database site!. Creative Commons. Mountain View, California, USA. Blog.
ScanCode Project (ongoing). ScanCode Toolkit Documentation. Covers both code and data licenses.
Schmitz, Patrice-Emmanuel and Giorgio Cacciaguerra Ranghieri (14 November 2018). Joinup Licensing Assistant — White paper v1.00. Brussels, Belgium: Unit.D2 (Interoperability Unit), European Commission. [Note that v1.01 is current but not available from the Commission website.]
Schweizer, Mark (5 November 2015). C‑490/14 — Verlag Esterbauer: Get off my map!. The IPKat. London, United Kingdom.
Smith, McCoy (no date). OSI permissive licenses: grammatical/textual analysis. USA: Intel Corporation. PDF forwarded by email.
Su, Andrew (2 August 2016). Open data should mean CC0, not CC‑BY. The Su Lab, Scripps Research Institute. La Jolla, California, USA.
US Copyright Office (November 2017). The Compendium of US Copyright Office Practices — Third edition: Chapter 700. US Government. Refer §727 covering databases.
van Eechoud, Mireille (1 April 2021). “A serpent eating its tail: the Database Directive meets the Open Data Directive”. IIC — International Review of Intellectual Property and Competition Law. 52 (4): 375–378. ISSN 2195-0237. doi:10.1007/s40319-021-01049-7. Editorial.
Wiese, Frauke, Ingmar Schlecht, Wolf‑Dieter Bunke, Clemens Gerbaulet, Lion Hirth, Martin Jahn, Friedrich Kunz, Casimir Lorenz, Jonathan Mühlenpfordt, Juliane Reimann, and Wolf‑Peter Schill (15 February 2019). “Open Power System Data: frictionless data for electricity system modelling”. Applied Energy. 236: 401–409. ISSN 0306‑2619. doi:10.1016/j.apenergy.2018.11.097. Postprint.
Wilbanks, John (20 June 2008). “Public domain, copyright licenses and the freedom to integrate science”. Journal of Science Communication. 7 (2): 1–10. ISSN 1824‑2049. doi:10.22323/2.07020304.
About the author
The author has been involved in energy system modeling since 1995 and open source energy model development since 2003. And from 2017, has participated in the Free Software Foundation Europe (FSFE) Legal Network, a nonpublic mostly online community of open source lawyers and technologists focusing on open source software and more recently open data. The author has coordinated four community submissions on open data and public sector information as part of public consultation undertaken by the European Commission.
▢
