Hi
I am trying to model a CHP (1 input, 2 outputs) using the csv reader, but I think I am doing it wrong, because it’s not working.
The CHP I want to model has natural gas in input, electricity and district heat as outputs.
Here’s how I did:
class label source target
Transformer CHP_natgas GL_resource_natgas CHP_natgas
Transformer CHP_natgas CHP_natgas bus_el
Transformer CHP_natgas GL_resource_natgas CHP_natgas
Transformer CHP_natgas CHP_natgas bus_th_dh
Do you have suggestions?
thanks
gabriele
Hi Gabriele,
if you are using oemof 0.1.4 as you mentioned in the other topic, the class should be named “LinearTransformer” and not “Transformer” as the class has been renamed from v.0.2.0 upwards.
Make sure that you use the documentation for v0.1.4.
Best wishes,
Cord
1 Like
In the long run I would recommend to use oemof v0.2.x and an excel-reader. It is much easier to debug from my point of view. See the excel reader example for more details.
Thank you Uwe. I looked at the example and it is clear. I think I will try to implement the model directly in oemof 0.2.
However, in case I have a Transformer (let me take the R1_pp_gas from scenario.xls), and it produces both electricity (R1_bus_el) and heat (e.g. I introduce R1_bus_heat) I should simply add 1 row in the excel indicating the same label (R1_pp_gas), the same from_bus (GL_bus_gas), but the second to_bus (R1_bus_heat), together with relative efficiency, capacity,etc., is it correct?
gabriele
| index |
from |
to |
efficiency |
capacity |
simultaneity |
variable costs |
| R1_pp_uranium |
GL_bus_uranium |
R1_bus_el |
0,325 |
5000 |
0,85 |
0,5 |
| R1_pp_lignite |
GL_bus_lignite |
R1_bus_el |
0,38 |
5000 |
0,85 |
4,4 |
| R1_pp_hard_coal |
GL_bus_hard_coal |
R1_bus_el |
0,38 |
5000 |
0,85 |
4 |
I just tried to be close to the old csv-example to make it easier to see the difference. In a new excel-example with chp-plants I would add/change columns, e.g.:
| name |
source |
elec_bus |
heat_bus |
capacity_boiler |
efficiency_elec |
efficiency_heat |
variable costs |
| R1_pp_gas |
GL_bus_gas |
R1_bus_el |
R1_bus_heat |
5000 |
0,40 |
0,5 |
0,6 |
| R1_pp_lignite |
GL_bus_lignite |
R1_bus_el |
R1_bus_heat |
5000 |
0,38 |
0,45 |
0,4 |
But this is just another example. The excel reader belongs to your model. First you create an excel-sheet that meets all your needs. Than you can adapt the excel-reader. In my model I have one electricity bus for each region therefore I do not need the electricity column. I have a column “region” and the electricity bus is always “region_elec_bus”.
It is important to understand that you can create your own excel reader but the example will help you to understand how this can be done. You just have to assign each column to an class-attribute. If you have different types of transformer you can create two tables or you can add a column with an identifier. In my model I have a column “type” which can be “fixed” and “variable” (for a fixed or variable heat/electricity ratio). In the excel-reader I group the table (groupby method of pandas) by this column and create a Transformer for all fixed-types and an ExtractionTurbineCHP for all variable-types.
Give it a try and write me if you have further questions.
It seems to be a little more effort but therefore you get a perfectly adapted excel-sheet for your model.
You can also use a Multiindex in your excel-sheet. Values are fiction.
Clear,
thank you.
I’ll follow your suggestion and try to adapt my model to the sheet.
Hi Uwe
I tried to adapt my excel sheet to the excel reader but I still have some problems.
The excel sheet is like this one:
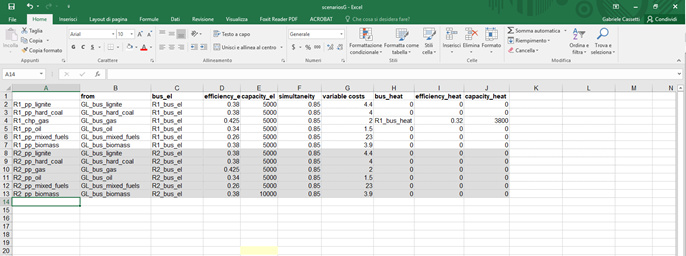
and I modified the excel reader as follows. after creating the R1_bus_heat:
[…]
for i, t in transformers.iterrows():
noded[i] = solph.Transformer(
label=i,
inputs={noded[t[‘from’]]: solph.Flow()},
outputs={noded[t[‘bus_el’]]: solph.Flow(
nominal_value=t[‘capacity_el’],
variable_costs=t[‘variable costs’],
max=t[‘simultaneity’]),
noded[t[‘bus_heat’]]: solph.Flow(
nominal_value=t[‘capacity_heat’])},
conversion_factors={noded[t[‘bus_el’]]: t[‘efficiency_el’], noded[t[‘bus_heat’]]: t[‘efficiency_heat’]})
I receive the KeyError: 0
I tried also this way:
[…]
for i, t in transformers.iterrows():
noded[i] = solph.Transformer(
label=i,
inputs={noded[t[‘from’]]: solph.Flow()},
el_outputs={noded[t[‘bus_el’]]: solph.Flow(
nominal_value=t[‘capacity_el’],
variable_costs=t[‘variable costs’],
max=t[‘simultaneity’])},
heat_outputs={noded[t[‘bus_heat’]]: solph.Flow(
nominal_value=t[‘capacity_heat’])},
conversion_factors={noded[t[‘bus_el’]]: t[‘efficiency_el’], noded[t[‘bus_heat’]]: t[‘efficiency_heat’]})
but still get the same KeyError, even if this way I am creating a new dict, if I am not wrong.
Do you have any suggestion?
Thank you
gabriele
The second block is wrong because there is not attribute el_outputs.
The first one looks fine at first glance (but you should use the code-bloc function of this forum).
To debug the block you could divide it.
for i, t in transformers.iterrows():
if noded.get(i) is not None:
print("Key {0} already exist.".format(i))
noded[i] = 5
from_bus = noded[t['from']]
el_bus = noded[t['bus_el']]
th_bus = noded[t['bus_heat']]
cap_el = t[‘capacity_el’]
[...]
in_flow = solph.Flow()
noded[i] = solph.Transformer(
label=i,
inputs={from_bus: in_flow},
outputs=...
In that way you can check the type and the value of any part. If everything is fine the creation of the class should be fine, too.
If you still do not succeed you can reduce the example to the necessary buses and this transformer-sheet and publish the code and the excel file anywhere or send it to me. So that I can have a look.
where can I send you the reduced code?
If I delete the heat bus the code works fine, if I add it as the electricity bus, it gives me error.
I think it could be related to the Transformer class.
PS. sorry to ask, how do I use the code bloc function?
```python
print(“This is my {0} code”.format(‘python’))
```
The code above leads to:
print("This is my {0} code".format('python'))
You just forgot to create a heat bus and you cannot connect a transformer to a non-existing bus. You could create all buses in advance or you can check if the bus exist and create it if necessary. The following loop should work:
for i, t in transformers.iterrows():
if t['bus_el'] not in noded:
noded[t['bus_el']] = solph.Bus(label=t['bus_el'])
if t['bus_th'] != 0:
if t['bus_th'] not in noded:
print(t['bus_th'])
noded[t['bus_el']] = solph.Bus(label=t['bus_th'])
noded[i] = solph.Transformer(
label=i,
inputs={noded[t['from']]: solph.Flow()},
outputs={
noded[t['bus_el']]: solph.Flow(
nominal_value=t['capacity_el'],
variable_costs=t['variable costs'],
max=t['simultaneity']),
noded[t['bus_th']]: solph.Flow(
nominal_value=t['capacity_heat'],
max=t['simultaneity'])},
conversion_factors={
noded[t['bus_el']]: t['efficiency_el'],
noded[t['bus_th']]: t['efficiency_heat']})
By the way your transformer is overdetermined. To avoid this (and errors or confusions) you could define chp plants with the input flow. You definitely do not need the heat capacity and the heat efficiency.
boiler_capacity = elec_capacity / elec_efficiency
heat_capacity = boiler_capacity * heat_efficiency
In your case the real(!) heat capacity is 3765 and not 3800 as mentioned in the excel sheet. Therefore I would avoid overdetermined input data, it is confusing!
Thank you.
Yes, in the excel the values are more or less random, I just wanted to see if the code ran. I specified both heat capacity and efficiency to include both condensing and back pressure mode of CHP, but probably it is better to use the component GenericCHP because it is better modelled.
However, I thought that all the buses were created by running the cells:
for i, b in buses.iterrows():
noded[b['label']] = solph.Bus(label=b['label'])
since I couldn’t see the explicit creation of bus_el as:
noded[t['bus_el']] = solph.Bus(label=t['bus_el'])
When is the bus_el created in the original code?
The excel-reader is more a concept than existing code. However, different example may help new user but there is no “original code”. It really depends on your needs. You can always check/create all needed buses before you create a component or you can create all buses beforehand. The example in the repository is just one example and it is an older one. I would not do it like this any more. You do not need any additional information to create a bus and therefore I would not add an extra sheet just for the buses. But you can do what ever you want once you have understood the concept. You can rename the columns to your needs etc.
You only should avoid redundancies (the same value in different cells) and overdetermined classes (s. above). Even though you may think everything is in line in the beginning but after a month you may forget which values depend on each other. This is very error-prone.
You should keep in mind that the GenericCHP can be more precise but may produce an MILP instead of an LP. This will increase the solver time and the memory usage. The transformer for back-pressure or block devices and the ExtractionTurbineCHP for extraction turbines or back-pressure with an additional cooling devise might be enough for large models and avoid mixed-integer. But you can try it out and share your experience.
I think we should change the title to “Modelling chp plants with the excel/csv-reader” to make it easier for people with similar problems to find this thread.
Hi Uwe!
is the topic correctly marked as solved?
thanks! 
Yes  Thank you for your contribution.
Thank you for your contribution.
Hello all,
even though the issue is solved I also have a question regarding the Excel Reader.
Every value that I leave blank in the Excel sheet is transformed into ‘nan’ by Panda after the initial parsing. I want it to be ‘None’ so it doesn’t conflict with other values (None as: value=None ; not meant as a ‘string’). Is there an easy solution? I don’t want to parse through all cells etc. but I can’t find the Option in the Panda doc.
You can replace NaN values with a value using the fillna method. But you cannot replace them with None because NaN is the table equivalent to None. You could replace NaN with zero.
What conflict do you have with NaN values and why do you think you will not have these problems if you have None instead of NaN?
for i, s in storages.iterrows():
if s['Investment'] == 1 :
noded[i] = solph.components.GenericStorage(
label=i,
inputs={noded[s['bus']]: solph.Flow(variable_costs=s['variable_costs'],
investment = solph.Investment(ep_costs=economics.annuity(capex=s['capex_pump'], n=s['calendaric_lifetime'],wacc=s['wacc'])), max=s['max_power'])},
outputs={noded[s['bus']]: solph.Flow(variable_costs=s['variable_costs'],
investment = solph.Investment(ep_costs=economics.annuity(capex=s['capex_turbine'], n=s['calendaric_lifetime'],wacc=s['wacc'])), max=s['max_power'])},
capacity_loss=s['capacity_loss'],
initial_capacity=s['initial_capacity'],
capacity_max=s['max_capacity'],
capacity_min=s['min_capacity'],
inflow_conversion_factor=s['efficiency_pump'],
outflow_conversion_factor=s['efficiency_turbine'],
nominal_input_capacity_ratio = s['input_capacity_ratio'],
nominal_output_capacity_ratio = s['output_capacity_ratio'],
invest_relation_input_output_power = s['relation_input_output_power'],
investment = solph.Investment(ep_costs=economics.annuity(
capex=s['capex_capacity'], n=s['calendaric_lifetime'],wacc=s['wacc'])),
)
I am still using my Version of the components class I pushed (FYI) and there the constraint can’t handle the 0 when it Comes to the invest_relation_input_output_power since it would prohibit to invest in any flow at all. If I leave it blank the constructor doesn’t take the Default value None but instead uses nan which results in an error.
In the end it will falsely be in the set that creates the constraint that couples Input to Output power? If not I can of Course just delete the error and it will work just fine.
For now I iterate over the storage dataframe and just replace nan with None. This works just fine, but I was wondering if there is an easier way implemented within Panda.

 Thank you for your contribution.
Thank you for your contribution.