Hello everyone,
I am building a regional, hourly simple dispatch model of three countries, from which only one country is connected to two others (not each with each). I used the simple_dispatch example as a basis, and I added to it hourly defined electricity load, renewable production from cvs file (as nominal values), and some more power plants, by country. I was able to run it after connecting two countries, but when connecting the third one, I got a Memory error:
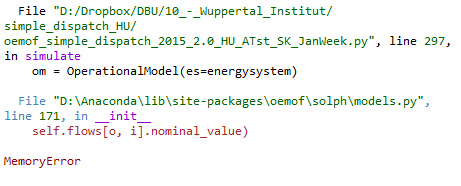
in models.py, line 171 in bold:
# ######################### FLOW VARIABLE #############################
# non-negative pyomo variable for all existing flows in energysystem
self.flow = po.Var(self.FLOWS, self.TIMESTEPS,
within=po.NonNegativeReals)
# loop over all flows and timesteps to set flow bounds / values
for (o, i) in self.FLOWS:
for t in self.TIMESTEPS:
if self.flows[o, i].actual_value[t] is not None and (
self.flows[o, i].nominal_value is not None):
# pre- optimized value of flow variable
self.flow[o, i, t].value = (
self.flows[o, i].actual_value[t] *
**self.flows[o, i].nominal_value)**
# fix variable if flow is fixed
if self.flows[o, i].fixed:
self.flow[o, i, t].fix()
if self.flows[o, i].nominal_value is not None and (
self.flows[o, i].binary is None):
# upper bound of flow variable
self.flow[o, i, t].setub(self.flows[o, i].max[t] *
self.flows[o, i].nominal_value)
# lower bound of flow variable
self.flow[o, i, t].setlb(self.flows[o, i].min[t] *
self.flows[o, i].nominal_value)
self.positive_flow_gradient = po.Var(self.POSITIVE_GRADIENT_FLOWS,
self.TIMESTEPS,
within=po.NonNegativeReals)
self.negative_flow_gradient = po.Var(self.NEGATIVE_GRADIENT_FLOWS,
self.TIMESTEPS,
within=po.NonNegativeReals)
I had similar, Memory error previously (when I had only one country in the model) and I managed to solve it with shorter (less characters) hourly data in the csv file. Now it is not helping any more, it goes further (takes more time), but then I get Memory error in the end again.
Is it possible, that three countries’ electricity data is too much for my computer with 8GB RAM? Or what else could be the problem? My memory is on full utilization indeed, when I run the model, which is unusual, and I have the feeling, that it shouldn’t.